Research Data Management
Understandably, research data management may be perceived as a troublesome task, but it offers many advantages. For example, good data management can:
- help your peers and yourself to understand your research project and its data
- make it easier to collaborate and share data
- make your research more visible, which in turn can lead to more citations
- make your research more transparent, reliable and reproducible
- avoid data loss.
Remember that you must always comply with AU's "Regulations for storing and managing research data".
Management at AU has also adopted 3 strategic goals in relation to researchers.
All researchers at AU must:
- relate to the FAIR data principles as well as to other outputs of research such as codes and methods.
- integrate data management into their research processes and thereby ensure transparency and integrity in the results of the research.
- contribute to good practice and clear standards for handling data as well as metadata throughout the life cycle of the research - e.g. data collection, curating and storing both during and after the completion of projects, including choosing licenses and using persistent indicators.
Get an overview of how to process data in the different phases of your research here.
Life Cycle for Research Data
The structure of the following follows this version of the data lifecycle.
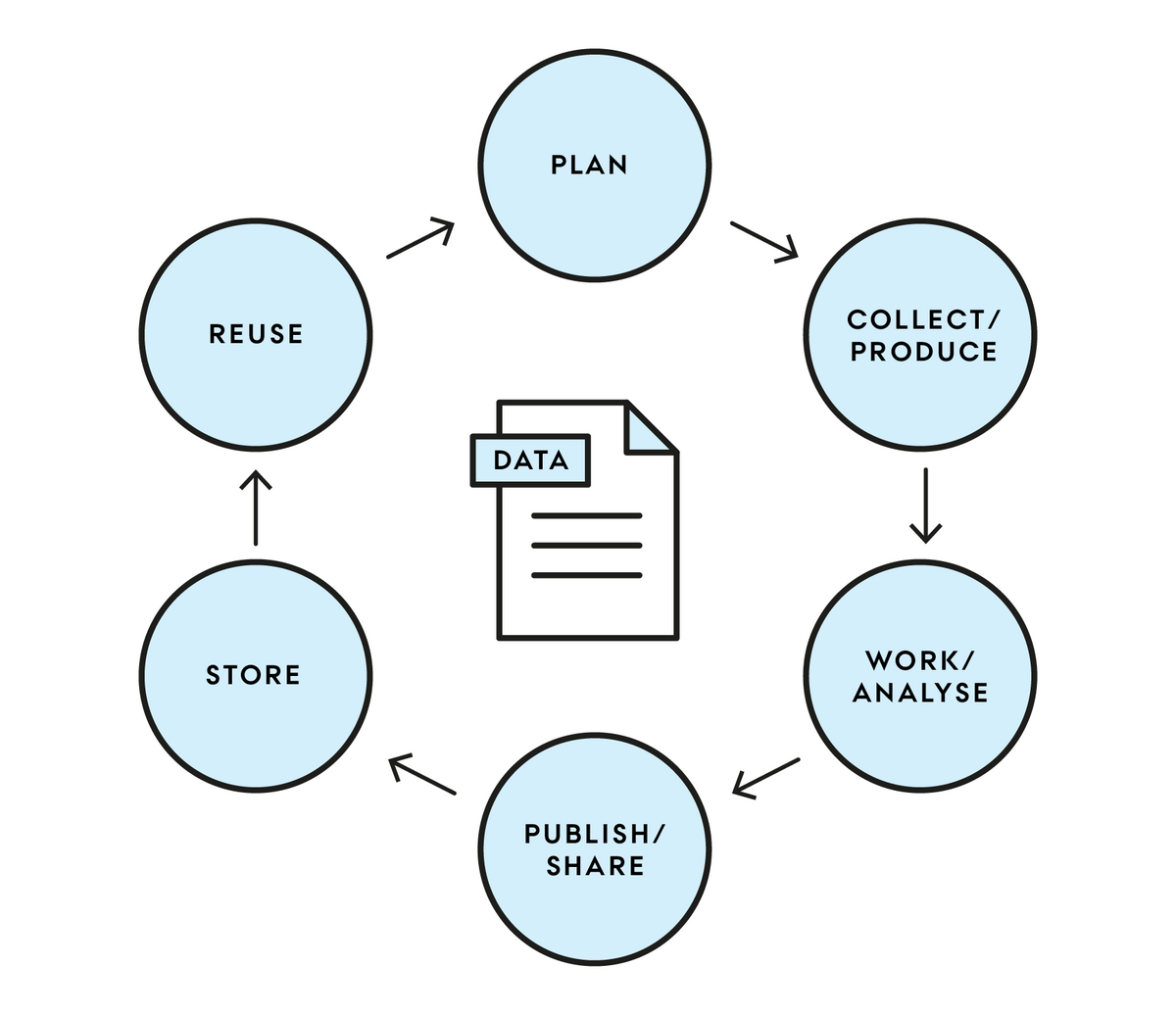
Plan
Plan
Considerations before you start
Considerations before you start
Before you start a research project, you should consider the type of data you will be working with. The data covered by AU’s Instructions for research data storage and management are listed below:
Personal data incl. pseudonymous data
- If you are going to work with general or sensitive personal data, there are a number of things to consider before your research project can start.
- Find out what general and sensitive personal data are.
Other types of restricted data
- Do you need to work on data with ethical or legal restrictions?
- See examples of data subject to restrictions.
- Ethical approval of research projects.
Types of unrestricted data
- All other types of data than those mentioned above, including anonymous data are not subject to any restrictions.
Check whether relevant data already exist
Check whether relevant data already exist
It is becoming more common to publish and share data sets. Therefore, find out whether data sets already exist that you can reuse or integrate into your research.
Some sources of possible data are listed under the Publication section further down this page.
Many use Zenodo, so you can also go directly there.
To search for suitable repositories, we recommend Re3data. Re3data.org covers both general and subject-specific repositories.
Prepare a data management plan (DMP)
Prepare a data management plan (DMP)
When you draw up a DMP, you comply with the principles of openness and transparency by documenting where data come from.
By describing who has created data and metadata, as well as when and under what conditions the data have been generated, a DMP helps to understand data and make research results reproducible.
A DMP describes the workflows data undergo in a large or small research project.
In general, it is a good idea to consider how you expect to collect, store and archive/publish data. Sometimes a funder will require that a DMP is attached to your application, and often funders have their own template. Therefore, find out whether the foundation to which you want to apply for funding has a requirement for DMP and its own template you can use.
A good DMP is a living document that is updated throughout the research process. A good DMP must be able to answer the following:
- Where will you store data?
- Will you take backup regularly and securely?
- Who is responsible for storage, backup and security of the data you collect?
- What steps have you taken to prevent unauthorised access to data?
DMP Online is a tool that guides you through preparation of a DMP. In collaboration with AU Library, AU offers support in DMP Online.
Collect/Produce
Collect/Produce
Integrated, existing environments and/or tools
Integrated, existing environments and/or tools
There are approved tools and/or integrated environments for a number of situations. Assistance will often be available from many sources. These include:
- Centre for Humanities Computing AU, ARTS offers assistance for researchers and is building an infrastructure to support all phases of research. Also builds data repositories.
- Center for integrated Register-based Research was established at Aarhus University in 2012 to promote interdisciplinary research within the social sciences, health sciences and certain areas of the natural sciences.
- Archaeological IT provides services in the fields of data collection, management and analysis for the cultural heritage sector. They act as a partner in connection with many large research projects and offer support and teaching for a number of organisations and projects.
- GenomeCentre (also nationally) GenomeDK is a national high-capacity unit with equipment to process data within bioinformatics and life sciences. The unit is headed by the Center for Genome Analysis and Personalized Medicine at Aarhus University.
AU IT can also help if, as a researcher, you have a special need in relation to a smaller IT solution or service. Please note that in general AU IT will establish all new IT solutions and services in the cloud.
Read more about AU IT's server services or contact your local IT support for help with cloud solutions.
At the start of the project, it is recommended that you decide what tool you want to use to document your collection and analysis. Several of the above have chosen one or more tools. The following can also be used:
- Jupiter Notebook
- e-lab books
NOTE! THE LIST IS REGULARLY UPDATED
Temporary storage of data collected/produced
Temporary storage of data collected/produced
When you collect data, it is important that you store the data in storage solutions approved for the type af data you are collecting. Find information about data classification and see where you can store different types of data.
You should use the university’s primary storage solution to store your research data. List of AU's data-storage solutions
Large amounts of data/increased security
Large amounts of data/increased security
In some cases, there may be a need for a special storage solution; either because you have a very large amount of data or if there are additional security measures that need to be met, for example if you are working with sensitive personal data.
If you have a special need AU IT can help you find a suitable storage solution. Please contact your local IT support team.
Backup
Backup
If you use AU’s network drive (U), shared drive/folder (O:) or AU’s SharePoint solution, you do not have to worry about back-up, as this is done automatically.
There are, of course, situations where data cannot be readily stored on network drives etc. For example when you collect data in the field, or while calculations are in progress. In such cases, you should make sure that the data is backed up as soon as possible. In the meantime, AU recommends that you use alternative encrypted back-up options, such as an encrypted USB flash drive. Read more about encryption.
You should use the university’s primary storage solution to store your research data. List of AU's data-storage solutions.
Collaboration on data
Collaboration on data
There are various solutions if you need to share your data with partners:
Teams and SharePoint
FileSender
- FileSender is a tool to send a file that is too large to be attached to an email.
- Log on to https://filesender.deic.dk/filesender/ with your WAYF login and upload your file. Select recipient and press send.
- The recipient will then receive an email with a link to download the file.
- It is also possible to send a so-called "upload voucher", which allows you to receive files from others.
- Upload may take several minutes, depending on your internet connection.
- Read more about the service at www.deic.dk/filesender.
Work/Analyse
Work/Analyse
Many programs can be used to analyse data.
Consider which program(s) you want to use to process/analyse data. You can choose to use the cloud solutions with computing and storage available from AU IT. You can activate and install different programs here. You can also use one of the other platforms available. Some of these are pure calculation and storage capacity, while others offer support for choice of methodology.
Integral milieus at AU
Integral milieus at AU
For a number of situations there are integral milieus at Aarhus University and often assistance is also offered. These include:
- Analytics Group - Aarhus BSS' local IT services where employees and students can receive help for analysis programmes in connection with research projects and written assignments.
- Centre for Humanities Computing AU, ARTS offers research IT services for employees at the Faculty of Arts and computational skills for students of Arts and Social Sciences.
- Centre for integrated Register-based Research CIRRAU is a centre established at Aarhus University in 2021 to facilitate interdisciplinary research in the academic areas of the social sciences, health sciences and elements from the natural sciences.
- Archaeological IT (page in Danish) offers services within data collection, data management and analysis for the cultural heritage sector. They are a partner in many large research projects and offer support and teaching for a number of organisations and projects.
- GenomeDK (also national) GenomeDK is a high-performance computing facility for bioinformatics and life sciences. The facility is led by the Centre for Genome Analysis and Personalised Medicine at Aarhus University.
Solutions for computing
Solutions for computing
DeiC coordinates the use of the national supercomputers available to Danish researchers. The supercomputers are run and developed by the universities, which make computing time available to researchers irrespective of their institutional affiliation.
Supercomputers (HPC) | Danish e-Infrastructure Cooperation (deic.dk)
As part of the national initiative, the eight universities will set up a local front office to provide support for HPC users at the universities. The national HPC centres and the back office in DeiC will collaborate with the local front offices to get users off to a good start with the HPC resources.
At AU, the DeiC front office is Sara Marie Westh, who you can contact via [email protected].
AU has a special role in connection with 2 of the HPC-centres and offers back office support for those.
Type 1: DeiC Interactive
Center for Humanities Computing Aarhus (CHCAA) - [email protected]
- Tickets can be submitted here: http://chcaa.io/#/contact
- Contact person: Kristoffer L. Nielbo - [email protected].
Type 2: DeiC Throughput
- Dan Ariel Søndergaard - [email protected]
Publish/Share
Publish/Share
When you have finished processing and analysing data, the research results must be shared, for example, in research records or books.
You can also share data in data journals or data repositories, so that others can reuse your data. In this way, you ensure that your data is used, quoted and licensed correctly.
In order to do this, you must ensure that the data is anonymous and that data is stored securely with a so-called persistent identifier (PID, DOI,...)
Unique identifiers
Unique identifiers
Research data is of great value to you, but also to other researchers. You can make it easier for others to refer to or use your research data by giving them a persistent identifier and by sharing your data with a clear license.
A PID (persistent identifier) is a unique key used to identify a given document, dataset or a person permanently.
Often, some descriptive metadata is linked to a PID. PIDs make it possible for others to find your data and refer them to them.
See: FAIR principles make PID data etc. findable and accessible (F and A in the FAIR principles).
Examples of persistent identifiers:
- DOIs (Document Object Identifiers) are used for documents, data and datasets. Most repositories can generate and maintain DOIs or other PIDs.
- Researcher IDs are another example of PIDs. They are used to ensure that a given person is not mistaken for someone else, for example with the same name, by assigning each individual a unique number. ORCID is an example of a researcher ID by which a person is given a unique number that can be used as an ID.
The conditions for accessing and reusing data must also be stated. This can be through using data licenses to show whether your data may be used by others, and how it may be reused (R in the FAIR principles).
Recommended formats
Recommended formats
Until anything else is decided, we refer to the Finnish National Digital Preservation Service's (DPS) list of recommended formats: File Formats (digitalpreservation.fi). An exception is made for EPUB and an addition of FITS is made. Further corrections to this list may occur.
Repositories
Repositories
Repositories can help make your data findable (the F in the FAIR principles).
They can guide you a long way towards making your research compatible with the FAIR principles. If you publish your data in an open repository, e.g. Dataverse or Zenodo, they will help you to:
- set up a DOI
- have fields for meta-data and descriptions that are relevant
- assign your data to a data license.
At AU, we don’t have an institutional repository, but there are many open repositories you can use. The choice will often depend on the subject area, but there are also several cross-disciplinary repositories.
Zenodo
- Zenodo is a general open access repository for data, software and publications for researchers who want to share their research results.
- It was developed and is owned by CERN and it is free of charge.
- All file formats are accepted, and you can upload up to 50 GB per data set.
- All data are assigned a DOI, and you can assign a license to your data.
- It is possible to upload data with limited access. Data are stored for the lifetime of the repository, and the program's lifetime is at least 20 years (from 2020).
- Zeno follows the FAIR principles.
Support:
Want to find out more?
Dataverse
- Harvard Dataverse is a free data repository for researchers from all disciplines.
- Data are automatically assigned to a DOI, and it is possible to restrict access to data.
- All datasets are automatically assigned to a Creative Commons license CC0, but this can be deselected.
- You can upload all file formats up to 2.5 GB and store up to 1 TB of data.
- Dataverse guarantees long-term storage, but without setting a specific time.
Support:
Want to find out more?
LOAR - The Royal Library Open Access Repository
- Library Open Access Repository (LOAR) is a repository for open data.
- LOAR was established in 2016 as a storage service for Danish research data.
- Researchers who upload data to LOAR are expected to do so under a Creative Commons license.
- Therefore, LOAR is not suitable for sensitive personal or copyright data.
- You can store up to 10 GB of data free of charge for five years.
- If you store more than 10 GB, or if your data has to be stored for more than five years, you can contact LOAR for prices.
- The Royal Danish Library provides support for users of LOAR.
- Read more:
Support
Want to find out more?
Mendeley Data
- Mendeley Data is a free repository for open data.
- Mendeley is owned by the publisher, Elsevier, and it supports all data formats and academic disciplines.
- Data are allocated a DOI and a license.
- It is possible to make data confidential or to set an embargo period.
- Data are stored in the cloud and can be exchanged via an open API.
- Individual datasets up to 10 GB can be uploaded.
- Permanent long-term storage is guaranteed.
- Mendeley follows the FAIR principles.
Support
Want to find out more?
Github
- Github is an open source collaboration platform for researchers, originally established to share and develop software.
- Github offers some services free and others for a fee.
- Free storage up to 500 MB.
Support
Want to find out more?
Journal publishers
Journal publishers
The major journal publishers usually work with selected repositories. Here are some of the publishers' recommendations:
- https://www.elsevier.com/authors/author-resources/research-data/data-base-linking
- https://www.nature.com/sdata/policies/repositories
- https://authorservices.taylorandfrancis.com/data-sharing-policies/repositories/
Licensing agreements with OA-publishing: https://pro.kb.dk/en/licensing
Licenses
Licenses
An author of a work may transfer all or part of his/her copyright through a license. There are different licences for different purposes.
Choosealicense.com has a list of the various licenses.
Creative Commons
- Creative Commons (CC) licenses are used to transfer a copyright.
- The licences allow the author to share his/her work with others under certain conditions.
Store
Store
In accordance with the Policy for research integrity, freedom of research and responsible conduct of research at Aarhus University, research data must be stored for a period of at least five years, unless another statutory storage period applies with regard to the research project, and the data requires longer storage.
Note that relevant legislation may be adjusted in collaboration agreements.
Research data may only be destroyed, anonymised and/or archived after they have been submitted in their entirety to the Danish National Archives or after one of the following conditions have been met:
- When the storage period has expired.
- Following a decision by the head of department/head of school.
- In accordance with the legal basis for collecting data.
In accordance with the Ministerial Order on the reporting of research data to the National Archives (please note the link is in Danish), Digital research data must be reported to the Danish National Archives when the research project concludes. In the case of data collections created by monitoring or continual collection of data, the data must be reported when data collection begins.
Here, digital research data are defined as data created in connection with research through the use of scientific method, along with associated documentation that explains the nature and content of the data, how the data has been obtained, and for what overall purpose.
All research data must be reported excepting the following types of data:
- Research data created through repeated experiments or simulations.
- Research data created solely through correlating data in administrative records.
- Research data published in their entirety in publications covered by the Act on statutory submission of published material in Denmark.
- Research data from projects below PhD level. Research data from PhD projects are not exempt from the reporting requirement and must be reported in accordance with the provisions of subsection (1).
Use this form to report your research data (virk.dk) (please note the link is in Danish).
AU’s options for storage of data in final form
AU’s options for storage of data in final form
AU has four different types of storage of data in final form. There is thus a solution for all data worth storing, regardless of the data’s form or how they are to be read.
Information about AU's storage solutions for data in final form.
Reuse
Reuse
The national strategy for research data management, which is based on the FAIR principles, advises that data be shared with other researchers as far as possible – that data be made FAIR.
If your data comply with the FAIR principles, others will be able to find and reuse them. If others are to know how they may use your data, it is important that you have linked a license to the data, describing conditions.
On www.howtoFAIR.dk, you can learn more about how you can make your research data more FAIR in practice.
Relevant websites
- The Danish Code of Conduct for Research Integrity
- Policy for research integrity, freedom of research and responsible conduct of research
- Data protection (GDPR)
- Classification of data